
The Scenario goes like this: A Synapps – SA Announce paging and messaging server integrated with Cisco’s CUCM hosting around 30 phone to phone paging groups. The paging had been working fine for months and out of no where one of thirty particular groups was putting in multiple trouble tickets over multiple days that the paging isn’t working.
So begins the troubleshooting and diagnosis. My first action was to monitor the paging server as it has a real time display of who is calling a paging group and which group they are calling at in given time. When I was monitoring this I could see multiple people calling multiple groups including the one in question. So this brings up one of those “what gives” questions. Are they just doing something wrong up in the area. Time to take a trip and raise that pedometer count.
I arrive in the area and try and locate and area where I can visually see and hear multiple phones. Easier said than done but in this case I was the only one available to work on the issue and knowing that the paging server will activate the speakerphone and mute lights when a group the phone is a member of is called this was my best bet and understanding what was going on. After making my first test page I can see that lights on the phones I can see are immediately lighting up, however I can’t hear audio. As I stand there dumbfounded with the phone still off hook all of a sudden the audio starts picking up the background noise. However, paging shouldn’t have a 6 second delay before you can start talking. Six seconds is a long time to wait after hitting page to start talking. So whats going on? It’s only one group experiencing this. What is different about their group? Time for a deep dive in the diagnostics world. Enter Wireshark.
[notice]TL;DR – HTTP access disabled on 30 of 100 phones with two HTTP attempts caused 6 seconds of delay before Synapps would start sending audio[/notice]
I first decided to grab a packet capture from the view of one of the phones in the non-working paging group. Having access to the closet and being on a Cisco IOS that doesn’t support the embedded packet capture I just set up a quick span port and used the mobile IP phone I had with me to make the calls. The problem area of the packet capture is in the image below. I had filtered for only traffic sourced from the paging server.
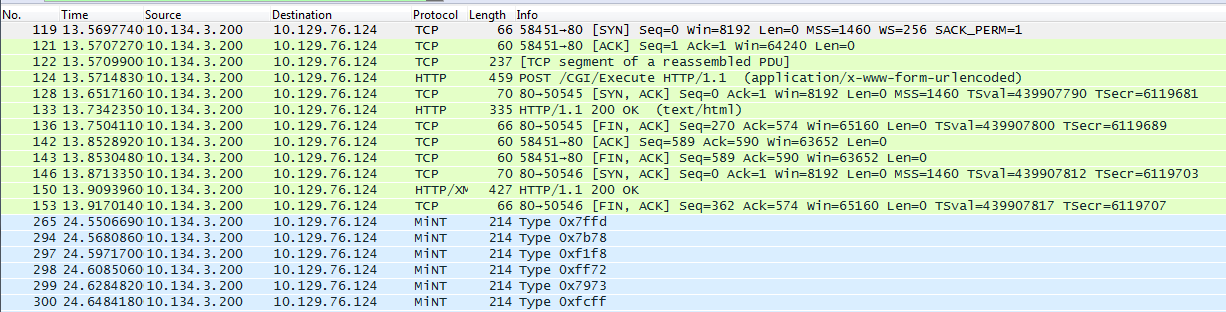
The above image doesn’t scream out any error but it does indicate the delay is indeed there if you look at the packet numbers on the left hand column. Focusing between the green and blue sections we can see that after the phone had received it’s HTTP/XML message to initiate the speakerphone and mute buttons there is a large number (112) of packets that come and go before the audio stream (indicated by the MiNT protocol packets in the blue section) begin to flow in. Again this doesn’t indicate the error itself, but it does correlate with the delay which is the root symptom of our users bad experience. Lets look at a packet capture from another phone in a different paging group not mentioning this issue.
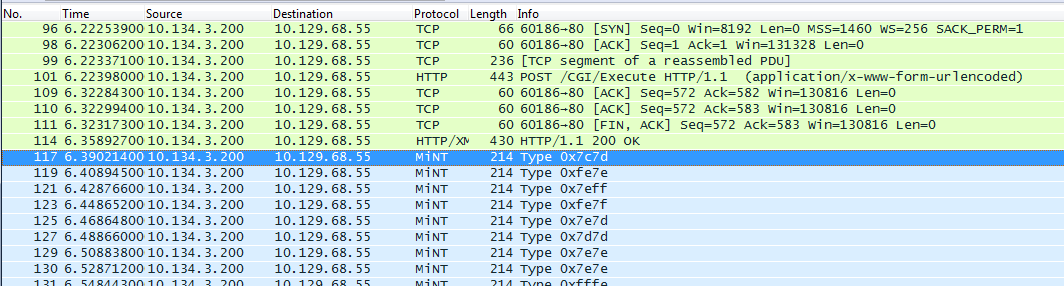
In the above packet capture from a known “good” paging group and phone we will look at the same things. Here we can see the phone receives its HTTP/XML off hook and mute message and within two packets begins receiving the audio stream. I mentioned in the first sentence the word good in quotation marks. This is because after final diagnosis of the issue this group was experiencing the delay issue as well but at a less noticeable timing. More on this later.
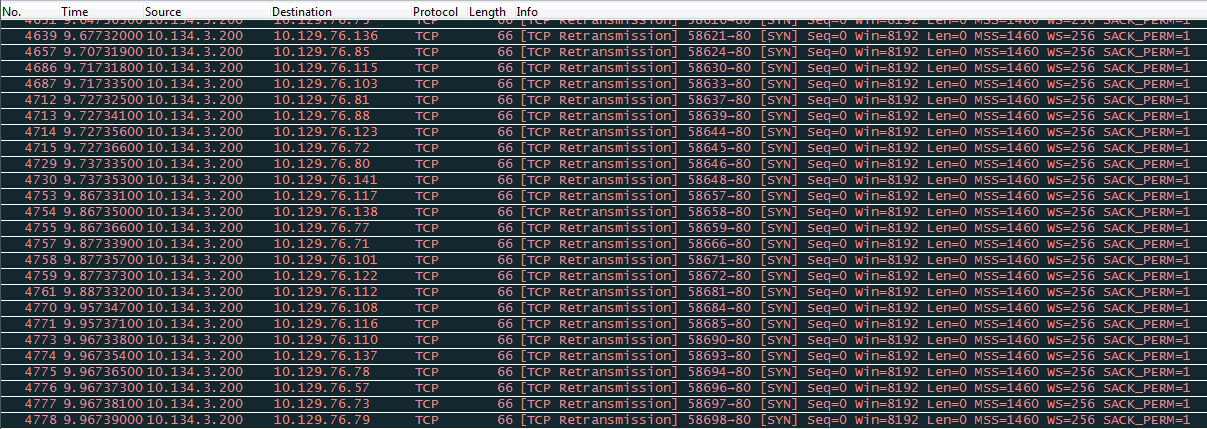
With a baseline indicating that there was indeed a rather large delay in the reporting users paging group I took to the Synapps server itself for a packet capture. Knowing that first, the server must send an HTTP/XML message to tell the phone to go off hook I filtered my packet capture to the subnet the phones in question were on. After this filter was applied and I started scrolling I came across this ugly block of black highlighted TCP Retransmissions. This is indicative to a problem if you ask me. At this point I took a report of phones that were part of the paging group and their IP addresses. Using a batch script to open each IP address in list in it’s own tab (it happened to be 111 phones which was slightly painful and chrome wasn’t too happy) I then started cycling through them. As it turns out there were thirty phones that were not responding and opening their webpages. I took this list and correlated it against CUCM finding that all of the phones not responding were of a particular model of phone.
At this point I needed to see if this was truly the issue from the Synapps point of view. I wanted to understand exactly what the paging server was trying to do. After digging through the settings I found that the paging server defaulted to a single HTTP retry with a 300 milliseconds. If we take this number and multiply it by the 30 phones we have that aren’t responding we get 9000 milliseconds and then multiply that by the first try, and the single HTTP retry and end up with roughly 18 seconds of delay. Now we need to keep in mind that that is a cumulative 18 seconds of delay and not a concurrent 18 seconds. This is because the paging server sends it’s first HTTP message to the first phone,and sends a message to the next phone while waiting for the responds from the first, and so on. All in all, with visual testing and timing the delay was roughly 6 seconds total.
After doing some digging into CUCM to find out why HTTP access was turned off on that particular model phone we had found that a common phone profile that was published to all of that model of phone cluster wide (to enable bluetooth) had been set to override the device default settings and in turn was disabling the HTTP access. After adjusting this setting and pushing it out to the house the paging group in question was functioning as desired. E.g. Press Page, and begin talking, no delay required.
This brings me back to my previous comment about the known “good” paging group. This group that seemed to be working was also experiencing the delay. The different is that out of it’s 30 phones it only had 2 of the model causing the delay. The problem group had 111 phones and 30 of them were of the model in question. This goes to prove that it is very possible to have an issue going on that is ghosting behind the scenes and not apparent until things get scaled out. I had fun with this troubleshooting exercise and proved to myself again the benefits of looking at packets from time to time even if there is no reported issue.